Excel-taulukkolaskenta sisältää usein solujen pudotusvalinnat tietojen syöttämisen yksinkertaistamiseksi ja / tai standardoimiseksi. Nämä pudotusvalikot luodaan käyttämällä tietojen validointitoimintoa määrittämään sallittujen merkintöjen luettelo.
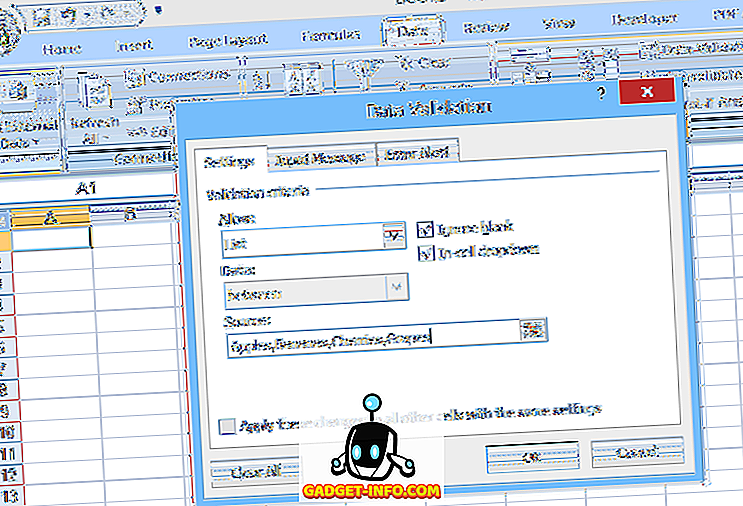
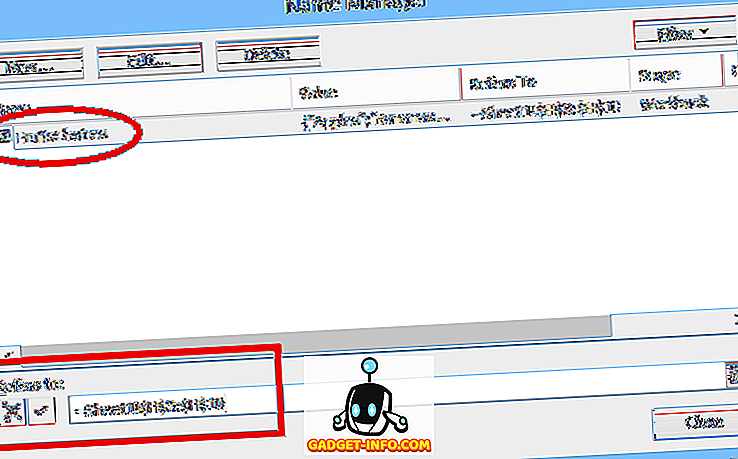
Voit määrittää yksinkertaisen avattavan luettelon valitsemalla solun, johon tiedot syötetään, ja napsauta sitten Data Validation ( Data- välilehdessä), valitse Data Validation, valitse List (Allow :) -kohdasta ja anna sitten luettelon kohteet (erotetaan pilkuilla) ) Lähde : -kentässä (katso kuva 1).
Tämän tyyppisessä perusluettelossa sallittujen merkintöjen luettelo määritetään itse tietojen validoinnissa; siksi, jotta käyttäjä voi tehdä luetteloon muutoksia, käyttäjän on avattava ja muokattava tietojen validointia. Tämä voi kuitenkin olla vaikeaa kokemattomille käyttäjille tai tapauksissa, joissa valintaluettelo on pitkä.
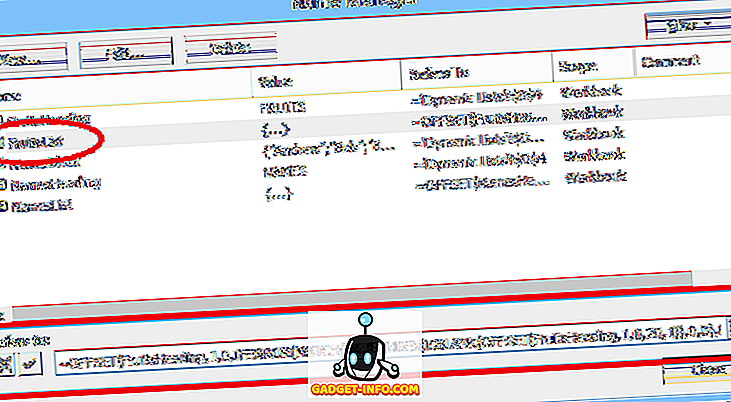
Toinen vaihtoehto on sijoittaa luettelo laskentataulukkoon nimettyyn alueeseen ja määritä sitten kyseisen alueen nimi (esivalinta yhtäläisellä merkillä) tietojen validoinnin Lähde : -kentässä (kuten kuvassa 2 on esitetty).
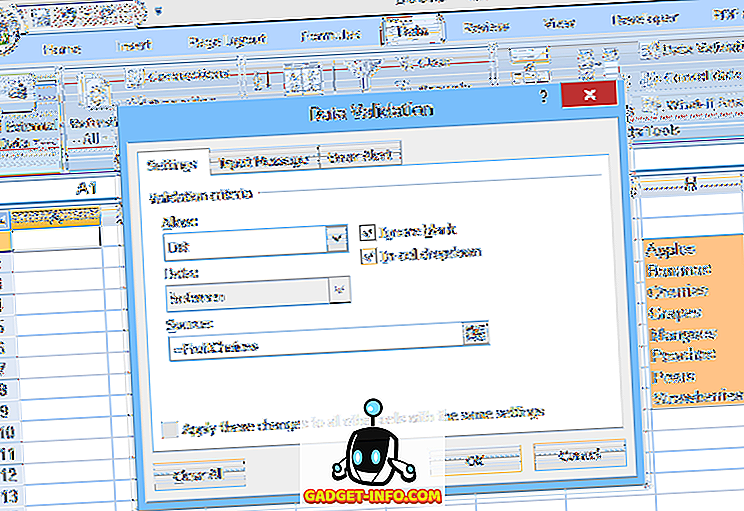
Tämä toinen menetelmä helpottaa luettelon valintojen muokkaamista, mutta kohteiden lisääminen tai poistaminen voi olla ongelmallista. Koska nimetty alue (FruitChoices, esimerkissä) viittaa kiinteään solualueeseen ($ H $ 3: $ H $ 10, kuten kuvassa), jos soluihin H11 tai alle lisätään valintoja, ne eivät näy avattavassa luettelossa (koska nämä solut eivät kuulu FruitChoices-alueeseen).
Samoin jos esimerkiksi päärynä- ja mansikka-merkinnät poistetaan, ne eivät enää näy pudotusvalikossa, vaan pudotusvalikossa on kaksi tyhjää vaihtoehtoa, koska pudotusvalikko viittaa edelleen koko FruitChoices-alueeseen, mukaan lukien tyhjät solut H9 ja H10.
Näistä syistä, kun käytät tavallista nimettyä aluetta luettelolähteenä pudotusvalikossa, nimetty alue täytyy itse muokata siten, että se sisältää enemmän tai vähemmän soluja, jos merkintöjä lisätään tai poistetaan luettelosta.
Ratkaisu tähän ongelmaan on käyttää dynaamisen alueen nimeä pudotusvalintojen lähteenä. Dynaamisen alueen nimi on sellainen, joka laajenee automaattisesti (tai sopimuksia), jotta se vastaa tarkasti tietolohkon kokoa, kun merkinnät lisätään tai poistetaan. Voit tehdä tämän käyttämällä kaavaa, joka ei ole kiinteä solualueen alue, jotta määritettäisiin nimetty alue.
Dynaamisen alueen määrittäminen Excelissä
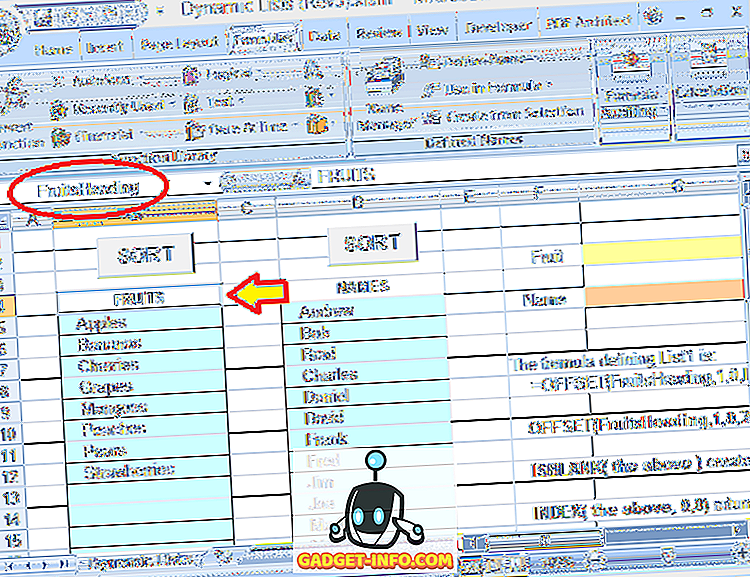
Normaali (staattinen) alueen nimi viittaa tiettyyn solualueeseen ($ H $ 3: $ H $ 10 esimerkissämme, katso alla):
Dynaaminen alue määritellään kuitenkin käyttämällä kaavaa (katso alla, otettu erillisestä laskentataulukosta, jossa käytetään dynaamisia alueen nimiä):
Ennen kuin aloitat, varmista, että lataat Excel-esimerkkitiedoston (lajittele makrot on poistettu käytöstä).
Tarkastellaan tätä kaavaa yksityiskohtaisesti. Hedelmien vaihtoehdot ovat solujen lohkossa, joka on suoraan otsikon alla ( FRUITS ). Tähän nimikkeeseen kuuluu myös nimi: FruitsHeading :
Koko kaava, jolla määritetään hedelmävalintojen dynaaminen alue, on:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TOSI, INDEX (ISBLANK (OFFSET (FruitsHeading, 1, 0, 20, 1)), 0, 0), 0) -1, 20), 1)
FruitsHeading viittaa otsikkoon, joka on yksi rivi luettelon ensimmäisen merkinnän yläpuolella. Numero 20 (jota käytetään kaavassa kaksi kertaa) on luettelon enimmäiskoko (rivien lukumäärä) (tätä voidaan säätää halutulla tavalla).
Huomaa, että tässä esimerkissä luettelossa on vain 8 merkintää, mutta niiden alla on myös tyhjiä soluja, joihin voidaan lisätä lisää merkintöjä. Numero 20 viittaa koko lohkoon, johon voidaan tehdä merkintöjä, eikä tosiasiallista merkintöjen määrää.
Nyt hajotetaan kaava palasiksi (jokaisen kappaleen värikoodaus), jotta voit ymmärtää, miten se toimii:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX) (ISBLANK ( OFFSET (FruitsHeading, 1, 0, 20, 1) ), 0, 0), 0) -1, 20), 1)
" Sisäinen " pala on OFFSET (FruitsHeading, 1, 0, 20, 1) . Tämä viittaa 20 solun lohkoon (FruitsHeading -solun alla), jossa valintoja voidaan syöttää. Tämä OFFSET-toiminto sanoo periaatteessa: Aloita FruitsHeading -solusta, mene alas 1 rivi ja yli 0 saraketta ja valitse sitten alue, joka on 20 riviä pitkä ja 1 sarake leveä. Joten se antaa meille 20-rivisen lohkon, jossa Fruits-valinnat syötetään.
Kaavan seuraava kappale on ISBLANK- toiminto:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX) ( ISBLANK (yllä), 0, 0), 0) -1, 20), 1)
Täällä OFFSET-toiminto (selitetty edellä) on korvattu ilmaisulla ”edellä” (helpottamaan lukemista). ISBLANK-toiminto toimii kuitenkin 20 rivin solualueella, jonka OFFSET-toiminto määrittää.
ISBLANK luo sitten 20 TRUE- ja FALSE-arvojen joukon, joka osoittaa, onko jokainen 20-rivisen alueen OFFSET-funktion viittaama solu tyhjä (tyhjä) vai ei. Tässä esimerkissä joukon ensimmäiset 8 arvoa ovat FALSE, koska ensimmäiset 8 solua eivät ole tyhjiä ja viimeiset 12 arvoa ovat TOSI.
Kaavan seuraava kappale on INDEX-toiminto:
= OFFSET (FruitsHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX (edellä, 0, 0), 0) -1, 20), 1)
Jälleen "edellä" viittaa edellä kuvattuihin ISBLANK- ja OFFSET-toimintoihin. Indeksitoiminto palauttaa taulukon, joka sisältää 20 TRUE / FALSE-arvoa, jotka on luotu ISBLANK-toiminnon avulla.
Indeksiä käytetään tavallisesti tietyn arvon (tai arvojen vaihtelun) valitsemiseen tietolohkosta määrittämällä tietty rivi ja sarake (kyseisen lohkon sisällä). Rivin ja sarakkeen tulojen asettaminen nollaan (kuten tässä tehdään) saa INDEX: n palauttamaan koko tietolohkon sisältävän taulukon.
Kaavan seuraava kappale on MATCH-toiminto:
= OFFSET (FruitsHeading, 1, 0, IFERROR ( MATCH (TRUE, yllä, 0) -1, 20), 1)
MATCH- toiminto palauttaa ensimmäisen TRUE-arvon sijainnin INDEX-toiminnon palauttaman taulukon sisällä. Koska luettelon ensimmäiset 8 merkintää eivät ole tyhjiä, taulukon ensimmäiset 8 arvoa ovat FALSE, ja yhdeksäs arvo on TRUE (koska 9. rivi alueella on tyhjä).
Joten MATCH-toiminto palauttaa arvon 9 . Tässä tapauksessa haluamme kuitenkin todella tietää, kuinka monta merkintää on luettelossa, joten kaava vähentää 1: n MATCH-arvosta (joka antaa viimeisen merkinnän sijainnin). Lopulta MATCH (TRUE, yllä, 0) -1 palauttaa arvon 8 .
Kaavan seuraava kappale on IFERROR-toiminto:
= OFFSET (FruitsHeading, 1, 0, IFERROR (edellä, 20), 1)
IFERROR-funktio palauttaa vaihtoehtoisen arvon, jos ensimmäinen määritetty arvo johtaa virheeseen. Tämä toiminto on mukana, koska jos koko solujen lohko (kaikki 20 riviä) on täynnä merkintöjä, MATCH-toiminto palauttaa virheen.
Tämä johtuu siitä, että kerromme MATCH-toiminnon etsimään ensimmäistä TRUE-arvoa (ISBLANK-toiminnon arvojen joukossa), mutta jos jokin soluista ei ole tyhjä, koko taulukko täytetään FALSE-arvoilla. Jos MATCH ei löydä tavoitearvoa (TRUE), jota se etsii, se palauttaa virheen.
Jos siis koko luettelo on täynnä (ja siksi MATCH palauttaa virheen), IFERROR-toiminto palauttaa sen sijaan arvon 20 (tietäen, että luettelossa on oltava 20 merkintää).
Lopuksi OFFSET (FruitsHeading, 1, 0, yllä, 1) palauttaa alueemme, jota etsimme: Aloita FruitsHeading -solusta, mene alas 1 rivi ja yli 0 saraketta ja valitse sitten alue, joka on kuitenkin monta riviä luettelossa on merkintöjä (ja 1 sarake leveä). Näin ollen koko kaava palauttaa alueen, joka sisältää vain todelliset merkinnät (ensimmäiseen tyhjään soluun).
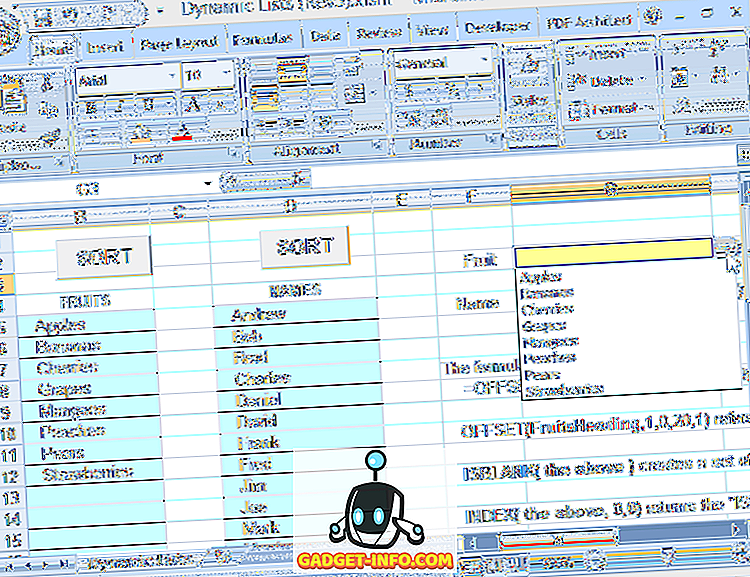
Tämän kaavan avulla voit määrittää luettelon, joka on avattavan avain lähde, voit muokata luetteloa vapaasti (lisätä tai poistaa merkintöjä, kunhan jäljellä olevat merkinnät alkavat yläsolusta ja ovat vierekkäisiä) ja pudotusvalikko heijastavat aina nykyistä luettelosta (ks. kuva 6).
Tässä käytetty esimerkkitiedosto (dynaamiset luettelot) on ladattavissa tältä sivustolta. Makrot eivät toimi, koska WordPress ei pidä Excel-kirjoista, joissa on makroja.
Vaihtoehtona luettelorivissä olevien rivien lukumäärän määrittämiselle, luettelolohkolle voidaan osoittaa oma kantansa nimi, jota voidaan sitten käyttää muokatussa kaavassa. Esimerkkitiedostossa toinen luettelo (Names) käyttää tätä menetelmää. Tällöin koko luettelolohkolle ("NAMES" -otsikon alla, 40 riviä esimerkkitiedostossa) annetaan NameBlock- alueen nimi. Vaihtoehtoinen kaava nimilistan määrittämiseksi on:
= OFFSET (NimetHeading, 1, 0, IFERROR (MATCH (TRUE, INDEX (ISBLANK ( NamesBlock ), 0, 0), 0) -1, ROWS (NamesBlock) ), 1)
jossa NamesBlock korvaa OFFSET (FruitsHeading, 1, 0, 20, 1) ja ROWS (NamesBlock) korvaa 20 (rivien määrän) aikaisemmassa kaavassa.
Joten pudota-luetteloissa, jotka ovat helposti muokattavissa (mukaan lukien muut käyttäjät, jotka eivät ole kokeneita), kokeile käyttää dynaamisia alueen nimiä! Huomaa, että vaikka tämä artikkeli on keskittynyt pudotusvalikoihin, dynaamisia alueiden nimiä voidaan käyttää missä tahansa, kun haluat viitata alueeseen tai luetteloon, joka voi vaihdella. Nauttia!